什么是爬虫
简介
爬虫(Web Crawler),也叫网络蜘蛛(Splider),是一种用来自动浏览www网页的程序。
爬虫一般从一个URL出发,访问所有关联的URL,并从中提取出感兴趣的内容。
爬虫访问网站的过程会消耗目标系统资源,所以有不少网络系统并不默许爬虫工作。因此爬虫要考虑到规划、负载,并且要讲『礼貌』(参考robots.txt)。
应用场景
爬虫主要有以下应用场景
- 科学研究
如数据挖掘、机器学习、图片处理等
- Web安全
如使用爬虫对网站是否存在某一漏洞进行批量验证、利用
- 产品研发
如采集各个商城物品价格,为用户提供市场最低价
- 舆情监控
如抓取、分析某社交平台的数据,从而识别出某用户是否为水军
- 搜索引擎
爬虫是搜索引擎的核心组成部分
爬虫策略
一个爬虫的实现主要由四大策略组成
- 选择策略
指定页面下载的策略,可细分为
链接跟随限制,指的是爬虫只搜索特定类型(如HTML)的资源,避免发出过多的请求。或者避免请求一些带有”?”的资源,避免从网站下载无限量的URLURL规范化,指的是以某种一致的方式修改和标准化URL的过程,避免资源的重复爬取路径上移爬取,指爬取每个URL里提示的每个路径,例如对于”http: //www.tac.cn/a/b/c.html",还会爬取"/a/b"、"/a"和"/"路径。主题爬取,指有条件地进行爬取(例如只爬取与python相关的页面)。 - 重新访问策略
网站是经常动态变化的,需要估算URL的
新鲜度和过时性,以确保是否需要重新访问。 - 平衡礼貌策略
使用爬虫可能导致一个
站点瘫痪,因此爬虫需要遵守一些协议来避免这个问题。 - 并行策略
并行运行
多个进程的爬虫时,为了避免重复下载页面,爬虫系统需要策略来处理爬虫运行时新发现的URL。
简单架构
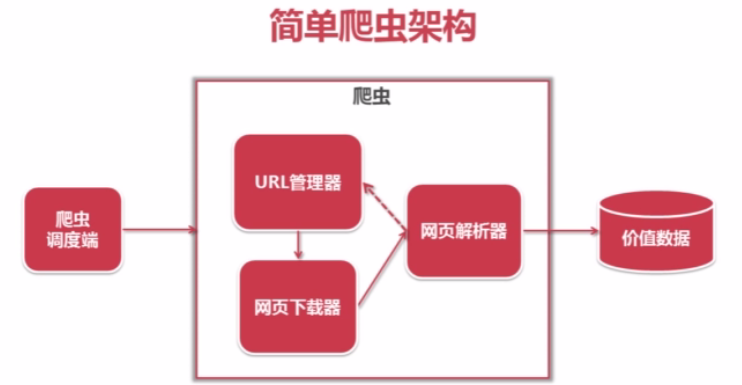
如图,一个最简单的爬虫架构至少包括爬虫调度端、URL管理器、网页下载器、网页解析器。这几个模块相互作用,从而提取出有价值的数据。其时序图如下
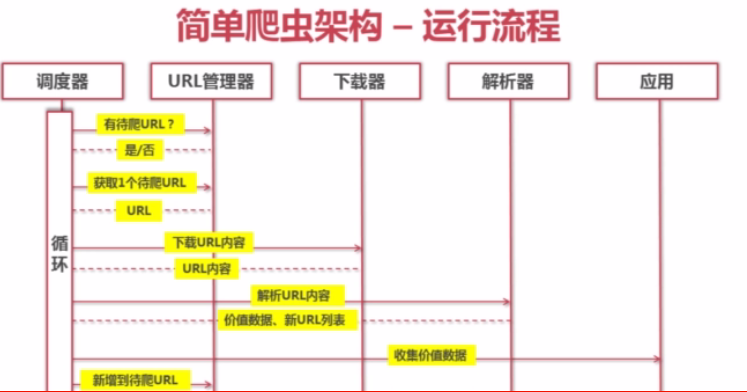
爬虫调度器从URL管理器中获取待爬取的URL,交由下载器进行下载。然后将下载器将下载的页面交由解析器进行解析,解析器又反过来将解析到的URL反馈给URL管理器。如此循环往复,直到没有待抓取的URL,则结束爬取。
——以上图片来自慕课网Python开发简单爬虫
URL管理器
管理待抓取的URL集合和已抓取的URL集合,防止重复抓取、防止循环抓取。
实现方式
- 内存
- 关系数据库
- NoSQL
网页下载器
- urllib2 python官方 *
- requests 第三方
网页下载分几种场景
- 直接通过url下载
- 需要添加请求参数,请求头(伪装浏览器)
- 需要伪装特殊情景,如cookie、proxy、https、http redirect
页面解析器
从网页中提取有价值数据的工具
python的网页解析器
- 正则表达式
- html.parser python官方
- beautiful soup4 第三方 *
- lxml