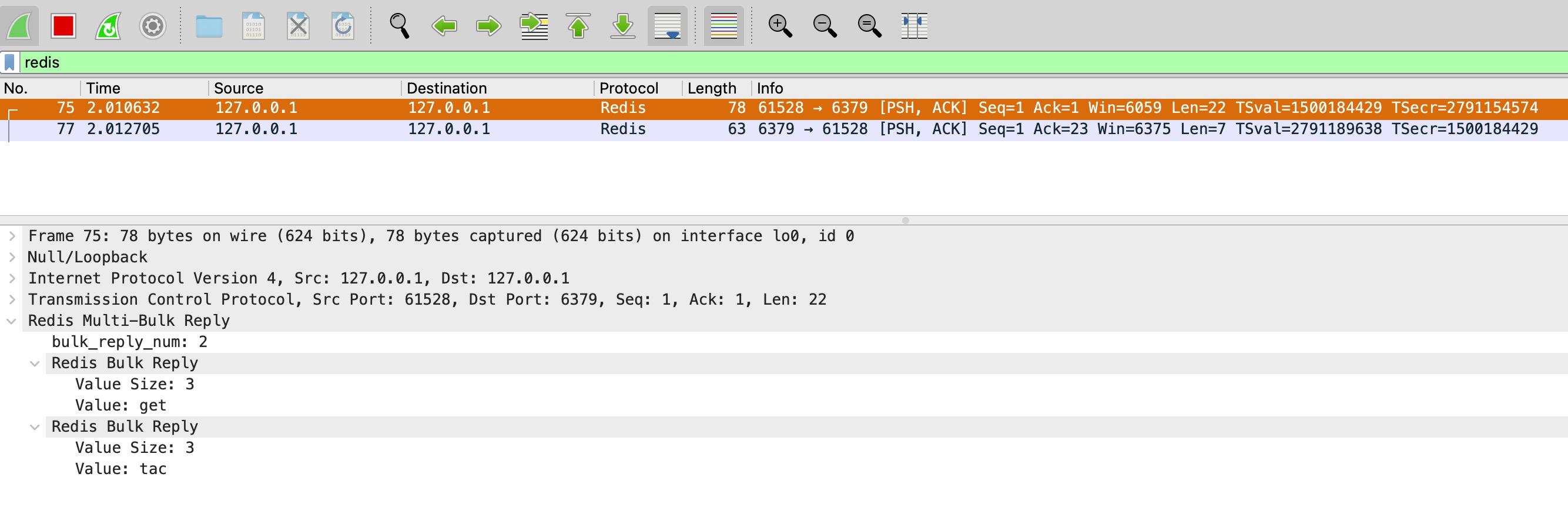
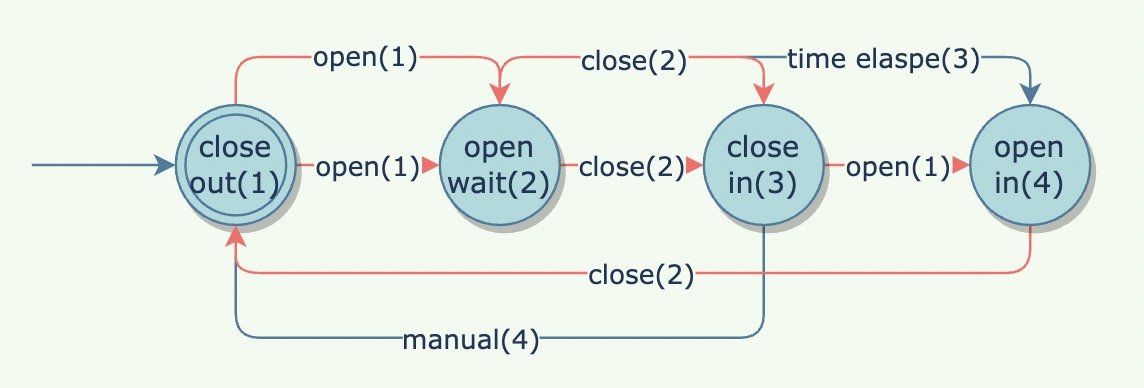
对比
如果只是简单地用在接口返回,List 与 Stream 并没有差异
例如以下两段代码,返回的结果是一样的
@GetMapping("list")
public Object listAll() {
return repository.findAll();
}
@GetMapping("stream")
public Object streamAll() {
return repository.streamAllBy();
}
但如果你需要在业务逻辑中处理大量的数据,List 和 Stream 的差异就体现出来了。
如果不用 Stream,在处理海量数据的时候,为了避免一次性将全部数据 Load 到内存导致内存溢出,一般我们会进行分页处理。但 skip & limit 跳页会导致较低的的查询性能,因此一般我们会采用 lastId 配合索引的方式来进行分页,如下所示
final int PAGE_SIZE = 5000;
String lastId = '000000000000000000000000';
List<MyDoc> rows = repo.findAllByGreaterThanId(lastId, PageRequest.of(0, PAGE_SIZE));
while (rows.size() > 0) {
for (row in rows) {
// do something for current row
}
// read next page
lastId = lastOne(rows).getId();
rows = repo.findAllByGreaterThanId(lastId, PageRequest.of(0, PAGE_SIZE));
}
但这种方式仍然存在一些问题:
- 仍然会占用一些内存(取决于你设定的 PAGE SIZE),当然这不是什么大问题
- 在等待传输完当前页数据的 I/O 期间,应用程序什么也干不了
- 如果哪天要修改成多线程版本以提升处理效率,会有比较大的改动
- 代码复杂度稍高
相比之下,如果我们用 Stream 来处理,代码就简单多了
repo.streamAllBy().forEach(doc -> {
// do something for cuurent row
});
如果要修改为并行版本也非常简单
repository.streamAllBy().parallel().forEach(doc -> {
// do something for cuurent row
});
Stream 的缺点:
- 批处理的场景下没有分页直观(例如滑动窗口),这点主要是 JDK8 缺乏支持,其它类似的框架如 RxJava 或 ProjectReactor 都是支持的,Spring Data Reactive 也有相关的支持(当然,学习成本也是很高。。)
- 【实际与我猜想的不一样,见实测章节】Stream 处理任务的期间会持续占用一个连接,不利于资源的复用。相比之下 List 只有每次拉取页的 I/O 期间才占用连接(假如不加事务的话)。如果连接资源很紧张,使用 Stream 可能会出较大的问题
性能实测
环境:
- 单 collection 约 130w 数据
- 客户端:Java + MacOS
List
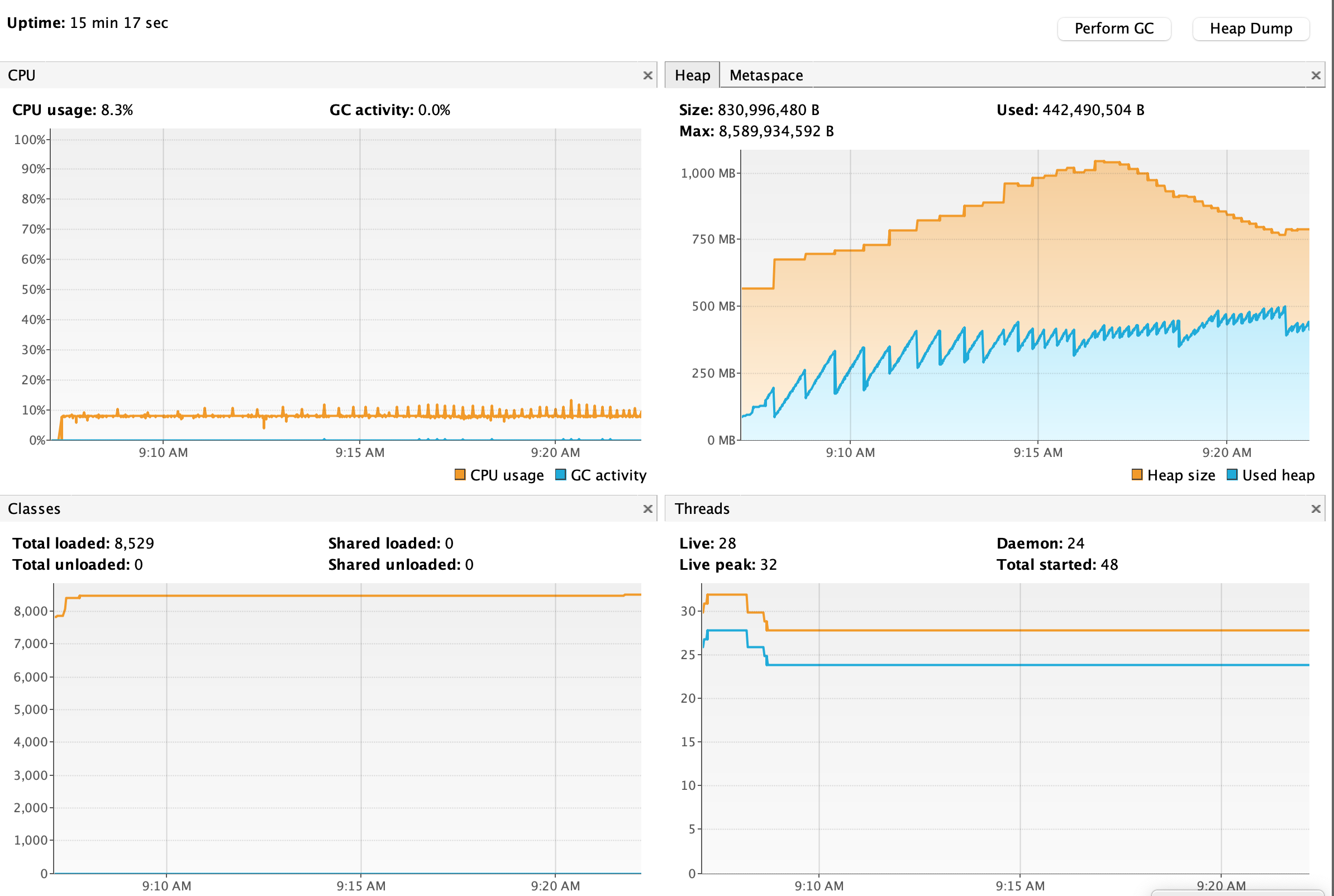
可以看到,调用 List 的过程,JVM 内存只增不减,且 GC 频率越来越高。整个过程花了接近 15min 时间。
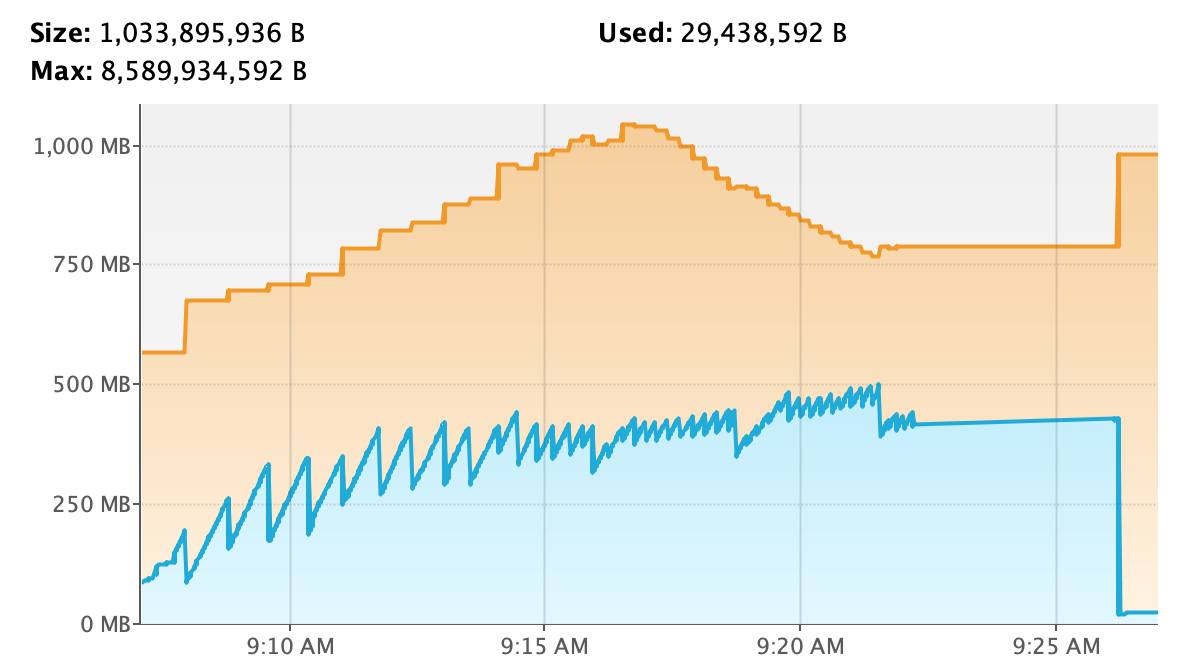
而在执行完后,触发一次 GC,直接内存占用就清零了。
原因显而易见,List 操作需要在 JVM 内存中构建 ArrayList 对象,加上数据量过于庞大,会导致不断地进行扩容,因此性能极差。同时由于所有数据均被一个 ArrayList 对象持有,导致内存占用只升不降(无法被 GC 回收)
Stream
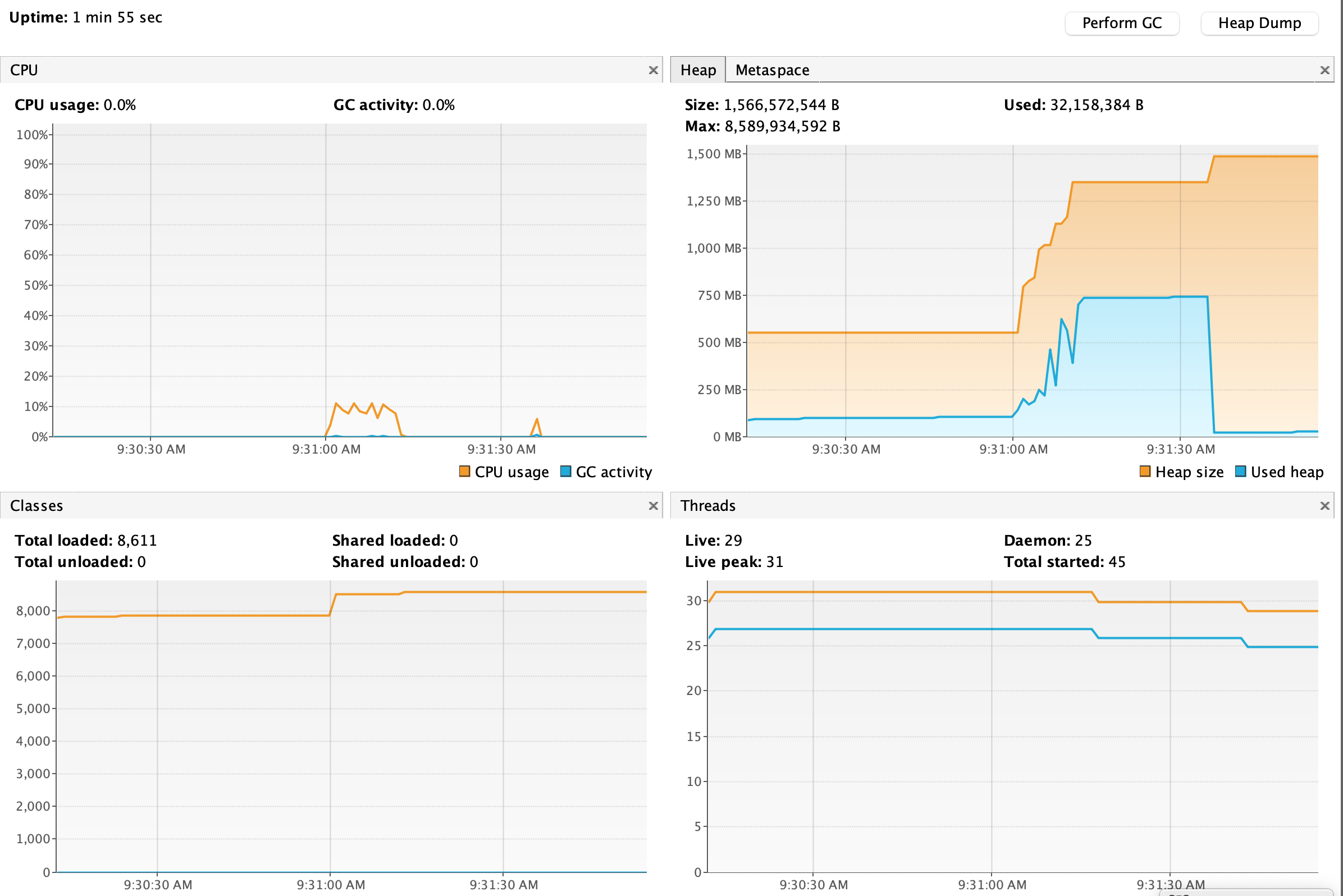
handle count: 1391665. time elapsed: 11500ms
首先性能上远远高于 List(没有扩容和 GC,只花了 11s 左右)
由于不需要通过 ArrayList 去保存数据,内存利用率会迅速增加(约 700MB),后面有一段维持直线的,猜测是因为一直没有触发 GC。
将代码稍微改动下,在 stream 的处理期间手动触发一些 GC
repository.streamAllBy()
.forEach(doc -> {
String itemInMemory = doc.getContent();
if (c.get() % 100000 == 0) {
System.gc();
}
c.getAndIncrement();
});
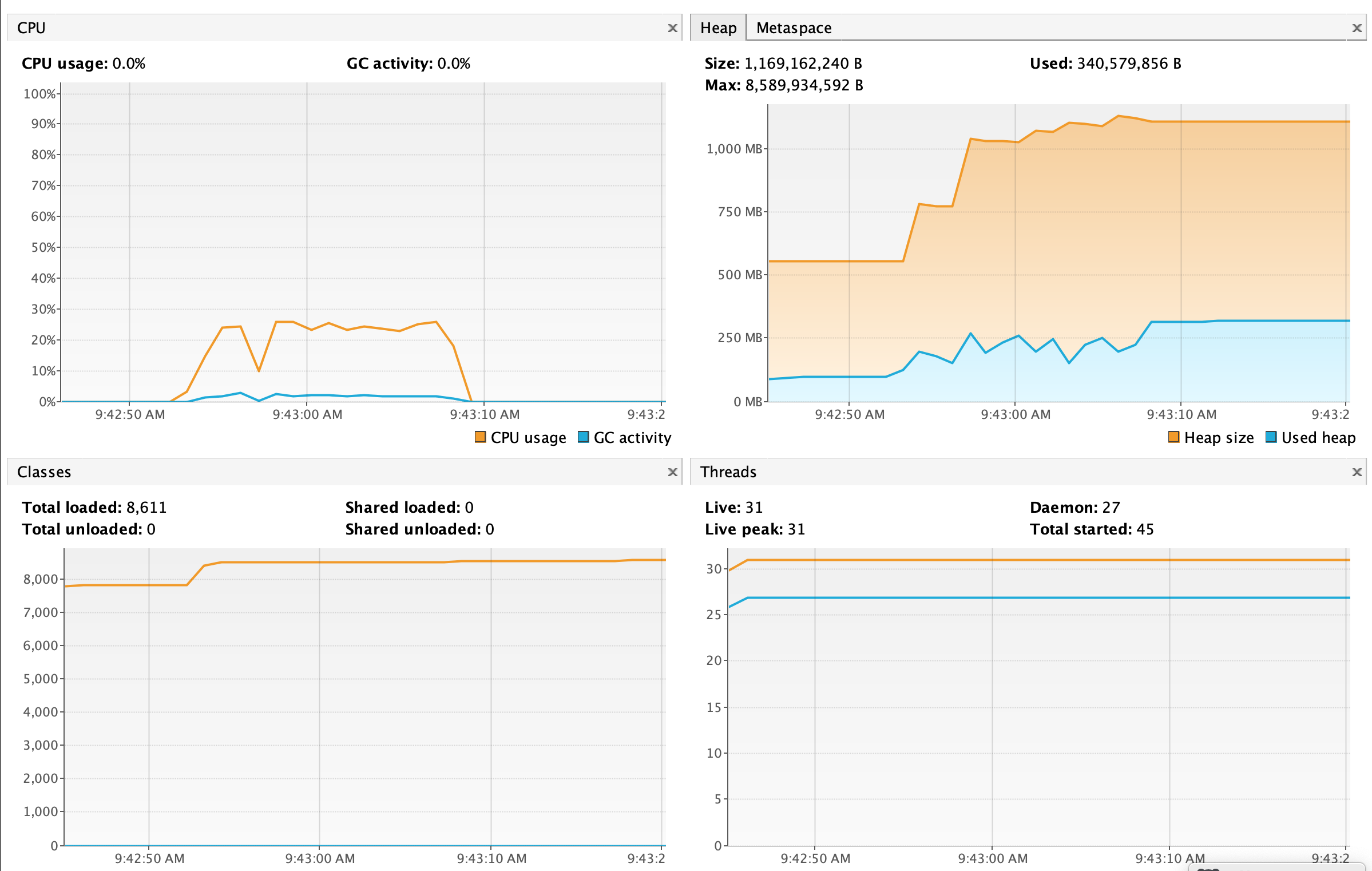
handle count: 1391665. time elapsed: 15226ms
可以看到相比于 List,Stream 的处理期间是可以释放被占用的内存的。另外由于多了取余和 GC 的操作,整个时间花费也由 11s 上升到 15s,CPU 也有所上升。
缺点 2 实测
为了验证上述的缺点 2,我准备了一个简单的服务以及两个接口
@GetMapping("list")
public Object listAll() {
return repository.findAll();
}
@GetMapping("stream")
public Object streamAll() {
repository.streamAllBy().parallel().forEach(doc -> {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
return "ok";
}
其中,/stream接口中针对每条数据会 sleep 200ms 的时间以模拟慢操作(数据库中预先准备了 100 条数据,因此该接口需要执行约 20s 的时间),/list接口则只是简单的返回所有数据。我们通过交叉用这两个接口来观察应用中的连接使用情况
- 我们先重启应用,确保连接池为空
- 先调用
/list接口,观察日志会发现 Spring Data Mongo 创建了一个连接
2023-01-20 17:09:19.576 INFO 77750 --- [nio-8080-exec-1] org.mongodb.driver.connection : Opened connection [connectionId{localValue:2, serverValue:1859}] to 192.168.11.180:32017
如果此时进入断点查看,会发现连接池数量为 1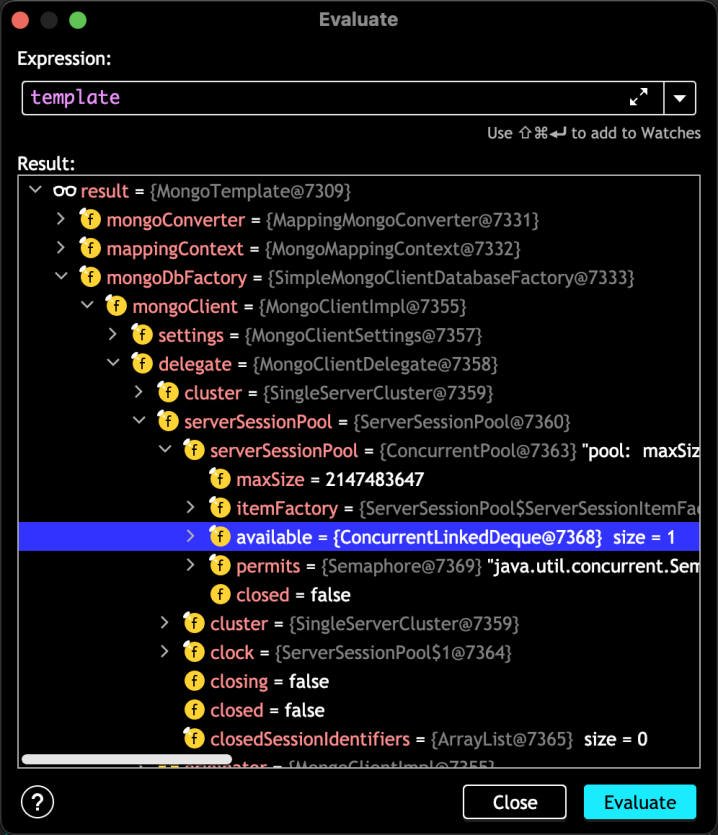
继续调用/list接口(非并发场景)会发现 Mongo Client 将一直复用此连接,不会创建新的连接。这符合连接池的设计机制
- 我们先调用
/stream接口,在其处理期间再调用/list接口,如果如我们所猜想的一样 Stream 会长时间占用一个连接的话,那么我们在调用/list接口的时候 Mongo Client 应该会再创建一个连接用于处理查询才对
实际情况是:在我们/stream接口执行期间,调用/list接口并没有使得 Mongo Client 创建新的连接。打断点观察ServerSessionPool的可用连接数也会发现其仍然为 1。显然 Mongo Client 及 JDK Stream 底层是针对这种情况做过优化的,猜想被推翻
- 为了证明在资源不够用的时候 Mongo Client 确实是会自动创建新的连接的,我们也用 ab 来做一个简单的压测
压测命令:ab -n 100 -c 5 'localhost:8080/mongo/list'
可以看到控制台输出了 4 个连接创建的事件
2023-01-20 17:19:42.172 INFO 77750 --- [nio-8080-exec-3] org.mongodb.driver.connection : Opened connection [connectionId{localValue:6, serverValue:1865}] to 192.168.11.180:32017
2023-01-20 17:19:42.172 INFO 77750 --- [nio-8080-exec-4] org.mongodb.driver.connection : Opened connection [connectionId{localValue:5, serverValue:1863}] to 192.168.11.180:32017
2023-01-20 17:19:42.172 INFO 77750 --- [nio-8080-exec-2] org.mongodb.driver.connection : Opened connection [connectionId{localValue:4, serverValue:1864}] to 192.168.11.180:32017
2023-01-20 17:19:42.172 INFO 77750 --- [io-8080-exec-10] org.mongodb.driver.connection : Opened connection [connectionId{localValue:3, serverValue:1866}] to 192.168.11.180:32017
断点观察连接池可用连接数也变成了 5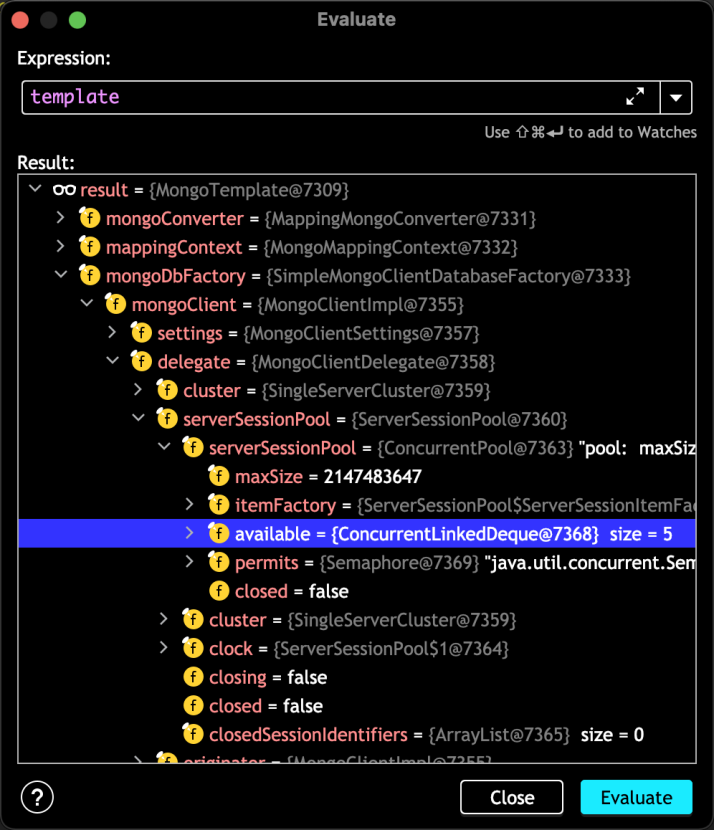
结论
除了如批处理之类的少数场景下,Stream 几乎总是优于分页 List(更不用说全量 List),因此在单次要处理的数据量达到一定量级时(比如超过 1000),应该优先考虑使用 Stream。