前言
虽然一直以来都用Maven作为java项目的构建工具,但早就听说过Gradle大名,于是今天终于抽出时间来了解一下这款号称结合了Ant和Maven优点的构建工具。
虽然Gradle支持多种语言,但这个系列的文章主要以Java项目构建为主。由于本人不是做Android开发,所以这个系列的文章可能会更偏向于Java Web开发视角。
学习资源推荐
官方Documentation 内容非常全面,缺点是全英文(对于英语差的同学简直是噩梦)
《跟我学Gradle》 Gralde中文用户组编写的中文系列教程,缺点是还不够完善,有些章节还没有内容
《Gradle In Action》中译版 书我没完整看过,只是查资料时读过几个章节,感觉内容还不错
概貌了解
同类工具比对
Ant
Ant是第一个“现代”构建工具,于2000年发布基于过程式编程的idea,具备插件功能及通过网络进行依赖管理的功能(结合Apache Ivy)。不足之处是采用XML作为脚本编写格式,不符合过程化编程的初衷。
Maven
Maven出现的目的是解决Ant带来的一些问题,发布于2004年。Maven依靠约定并提供现成的可调用的目标,首创了从网络下载依赖的功能。依然采用XML作为配置文件(因此同样有跟Ant一样难以定制化构建过程的缺点)。另外Maven虽然聚焦于依赖管理,但并不能很好地处理相同库文件不同版本之间的冲突(不如Ivy)。
Gradle
Gradle结合了两者的优点,并在此基础上做了许多改进。
Gradle使用基于Groovy的DSL编写构建脚本,可以更细致地控制编译打包过程(这也是为什么Android Studio默认采用Gradle作为构建工具的原因)。
Gradle对多模块项目有很好的支持。
Gradle支持多语言,包括java、groovy、scala、c++等。
Gradle使用Apache Ivy处理依赖,因此依赖管理方面优于Maven。同时Gradle可以使用多种类型的远程仓库,如Maven仓库、Ivy仓库。
关于DSL
DSL是Domain Specific Language的缩写,即领域特定语言。同字面上的意思,就是专用于处理某一领域问题的特定语言,例如用于web页面开发的HTML语言、用于GNU Emacs的Emacs Lisp等,甚至有一些简单的DSL只用于某个单应用程序(也称为Mini-Languages)。
由此可见,Gradle使用的DSL应该是一种专用于项目构建的语言。
更多内容
Getting Started - IntelliJ IDEA
初次接触为了能够快速看到效果,所以直接使用ide来入门。不过为了对Gradle有更深入的了解,往后的练习项目将全部使用命令行构建。
创建项目
- New -> Project -> Gradle,新建一个Gradle项目(就像Maven一样,IDEA内置了Gradle,所以不需要我们手动去安装了)
- 填写GroupId、ArtifactId、Version(这些跟Maven是一样的)
- 这里勾选上Create directories for empty content roots automatically选项,让IDEA帮我们创建好目录结构
- Finish,初次构建可能会花费较长的时间(跟Maven一样,要从网络下载一些东西,比如项目模板),构建好后的目录结构如下
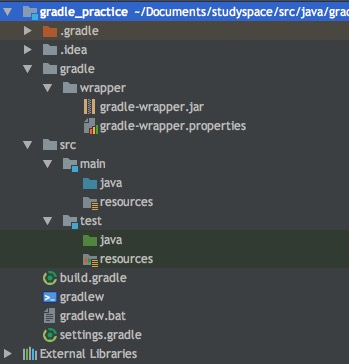
来看下各folder&file的含义:
- .gradle
Gradle相关的支持文件,一般不用关心
- gradle
- wrapper
The wrapper is a small script and supporting jar and properties file that allows a user to execute Gradle tasks even if they don’t already have Gradle installed. Generating a wrapper also ensures that the user will use the same version of Gradle as the person who created the project.
Creating New Gradle Project
大意为,wrapper里面是一些简单的脚本、使用户能在没有安装Gradle的情况下也能执行Gradle任务的supporting jar及properties文件等,同时wrapper还能确保用户执行Gradle任务时使用的版本与项目创建者使用的Gradle版本相同。总之是一个开发人员基本不需要关心的目录。
- src
源码目录,采用了与Maven相同的结构
- build.gradle
Gradle的构建配置文件(build file),需要我们编写内容(类似Maven的pom.xml)。
按照官方的描述,每个build.gradle都配置了一个org.gradle.api.Project类的实例,并且这个实例会有许多内建的方法和属性(稍后CLI项目中可以看到gradlew properties列出了一堆project的属性)。
build.gradle的DSL参考
- gradlew/gradlew.bat
分别用于类unix系统和windows系统下的wrapper脚本,之后可以看到,创建了wrapper后我们所有的指令都通过wrapper脚本来执行
- settings.gradle
与多模块项目配置有关的文件,用于描述项目模块之间的关系
Hello World
创建好项目后可以看到,已经有许多配置好的东西了,如junit依赖、Gradle wrapper等,所以现在已我们直接可以直接写单元测试
public class GettingStarted {
@Test
public void testSimply() {
System.out.println("hello gradle");
}
}
执行可以看到控制台输出
hello gradle
Getting Started - CLI
使用ide写个Gradle的Hello World确实非常简单,但使用CLI来搭建项目,能让我们对Gradle有更加深入的了解。
接下来我们将尝试用CLI写一个Hello World。
安装Gradle
由于我们这次用的是CLI,所以必须手动安装Gradle。
以我用的MacOS为例,打开terminal,run
$ brew install gradle
安装前必须确保安装了jdk1.7以上版本(我用的Gradle 4.1版本的要求),其它系统用户可以参考Installation
然后run,若已成功安装可以看到
$ gradle --version
------------------------------------------------------------
Gradle 4.1
------------------------------------------------------------
Build time: 2017-08-07 14:38:48 UTC
Revision: 941559e020f6c357ebb08d5c67acdb858a3defc2
Groovy: 2.4.11
Ant: Apache Ant(TM) version 1.9.6 compiled on June 29 2015
JVM: 1.8.0_121 (Oracle Corporation 25.121-b13)
OS: Mac OS X 10.12.4 x86_64
创建工程
创建一个空文件夹作为工程目录,同时创建一个build.gradle空文件
$ mkdir gradle_cli
$ cd gradle_cli
$ touch build.gradle
然后执行以下命令生成Gradle Wrapper
$ gradle wrapper
可以看到当前目录的变化
$ tree .
.
├── build.gradle
├── gradle
│ └── wrapper
│ ├── gradle-wrapper.jar
│ └── gradle-wrapper.properties
├── gradlew
└── gradlew.bat
现在可以通过wrapper脚本来执行各项任务,这样可以确保在更换了环境后依然能使用创建项目时使用的Gradle版本进行构建。
查看properties信息(以下输出做了大量删减)
$ sh gradlew properties
> Task :properties
------------------------------------------------------------
Root project
------------------------------------------------------------
allprojects: [root project 'gradle_cli']
ant: org.gradle.api.internal.project.DefaultAntBuilder@70e298ee
……
buildDir: /Users/tac/Documents/studyspace/src/java/gradle_cli/build
buildFile: /Users/tac/Documents/studyspace/src/java/gradle_cli/build.gradle
buildScriptSource: org.gradle.groovy.scripts.UriScriptSource@460e8e7a
……
depth: 0
description: null
displayName: root project 'gradle_cli'
……
gradle: build 'gradle_cli'
group:
……
plugins: [org.gradle.api.plugins.HelpTasksPlugin@23fb712b]
……
project: root project 'gradle_cli'
……
projectDir: /Users/tac/Documents/studyspace/src/java/gradle_cli
……
repositories: repository container
resources: org.gradle.api.internal.resources.DefaultResourceHandler@7cad9556
rootDir: /Users/tac/Documents/studyspace/src/java/gradle_cli
rootProject: root project 'gradle_cli'
……
state: project state 'EXECUTED'
status: release
subprojects: []
tasks: task set
version: unspecified
可以看到其中大多数属性都已经有了默认的值,这也恰好验证了Gradle约定优于配置的原则。
如果我们需要修改一些属性值,可以通过写build.gradle文件来进行配置
description = 'A Gradle build project for CLI'
version = '1.0'
group = 'cn.tac.test'
再次查看properties可以看到属性已经更改了
$ sh gradlew properties | grep -E "group|description|version"
description: A Gradle build project for CLI
group: cn.tac.test
version: 1.0
tip
- 你也可以先生成Wrapper再创建build.gradle,并不会有影响
- 除了手动创建之外,还可以通过
gradle init指令来初始化项目。初始化的内容包括执行gradle wrapper,以及自动生成build.gradle和settings.gradle,并且生成的文件里面已经有了一些自动生成的配置(默认是注释状态,即未启用)。
配置环境
由于我们是手动创建的空build.gradle,要构建java项目,我们还需要做一些简单的配置。
在build.gradle加入目标工程语言(上面提过,Gradle是支持多语言的)及版本、依赖及下载依赖的仓库的配置
apply plugin: 'java'
sourceCompatibility = 1.8
repositories {
mavenCentral()
}
dependencies {
testCompile group: 'junit', name: 'junit', version: '4.12'
}
tips
- 可以通过
dependencies任务查看当前项目的依赖信息。
Hello World
配置好环境后,我们创建源码目录及单元测试类
$ mkdir -p src/main/java src/main/resources src/test/java src/test/resources
$ cd src/test/java
$ mkdir -p cn/tac/test
$ cd cn/tac/test
$ touch HelloWorld.java
然后执行构建,如果不知道有哪些tasks可以执行,可以通过以下命令来查看
$ sh gradlew tasks
> Task :tasks
------------------------------------------------------------
All tasks runnable from root project - A Gradle build project for CLI
------------------------------------------------------------
Build tasks
-----------
assemble - Assembles the outputs of this project.
build - Assembles and tests this project.
……
Build Setup tasks
-----------------
init - Initializes a new Gradle build.
wrapper - Generates Gradle wrapper files.
Documentation tasks
-------------------
javadoc - Generates Javadoc API documentation for the main source code.
Help tasks
----------
……
Verification tasks
------------------
check - Runs all checks.
test - Runs the unit tests.
Rules
-----
……
$ sh gradlew build
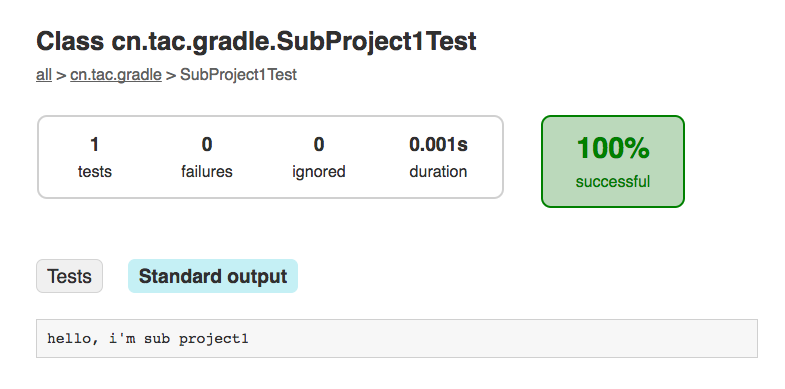
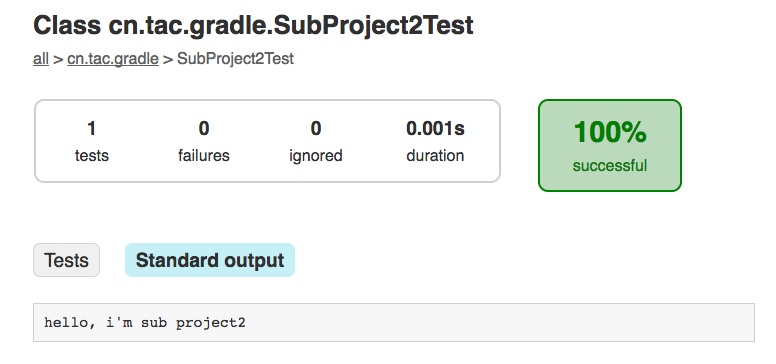
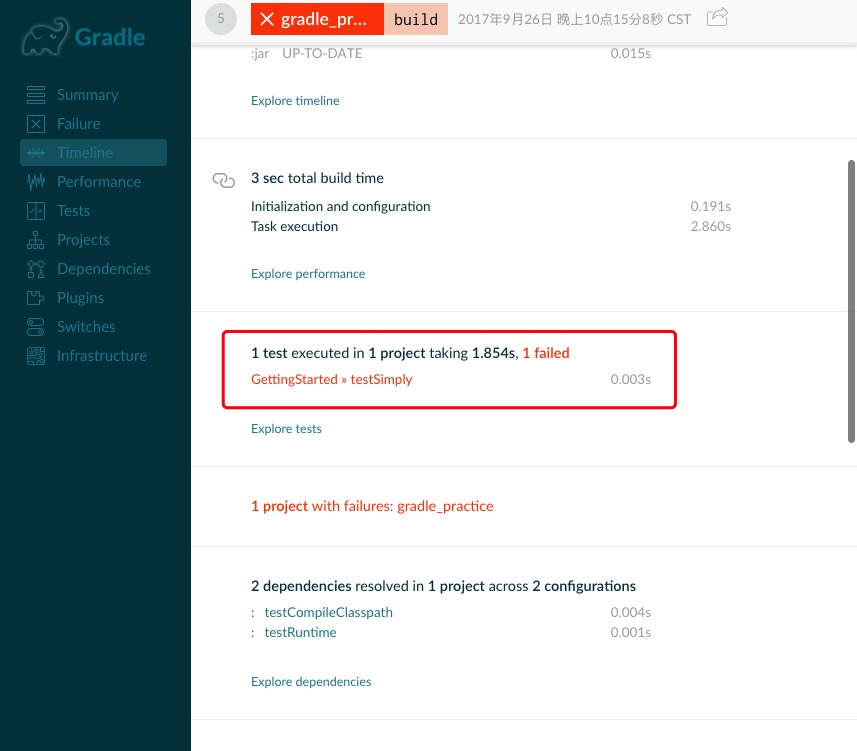
完了可以看见项目根目录下多了一个build目录,里面的内容就是执行构建的产物。与Maven不同的是,有个reports目录是Gradle生成的HTML格式的构建报告,可以通过浏览器打开查看
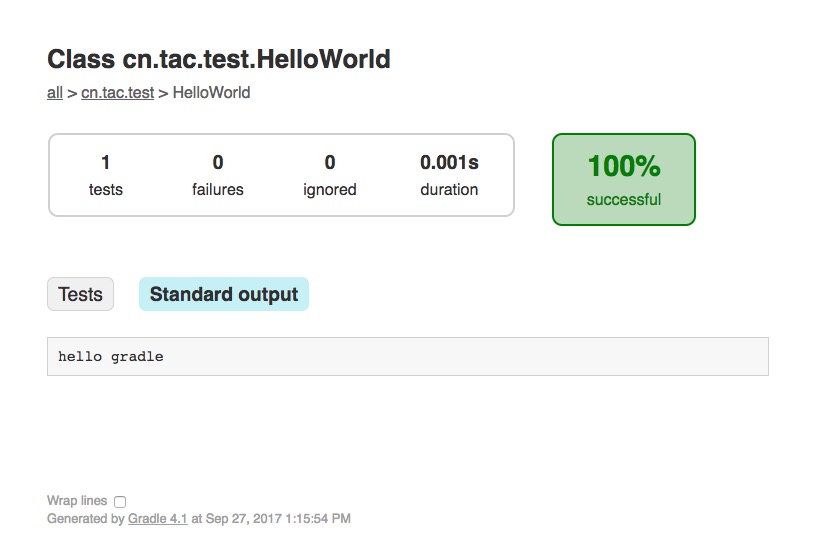
tip
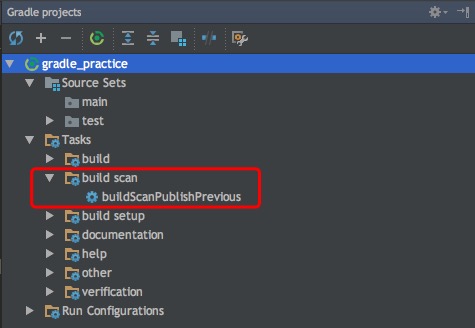
- 有没有发现sh gradlew tasks出来的列表有点像IDEA Gradle Project面板上的tasks节点?😃
- 在项目根目录下使用gradle跟gradlew执行task的效果基本是一样的,区别在于gradle会使用本地安装的Gradle版本进行构建,而gradlew会使用创建项目时使用的gradle版本进行构建,如果本地没有搜索到这个版本,则会自动下载